UNET SEGMENTATION¶
- UNet is a fully convolutional network(FCN) that does image segmentation. Its goal is to predict each pixel's class.
- UNet is built upon the FCN and modified in a way that it yields better segmentation in medical imaging.
1.1 Architecture¶
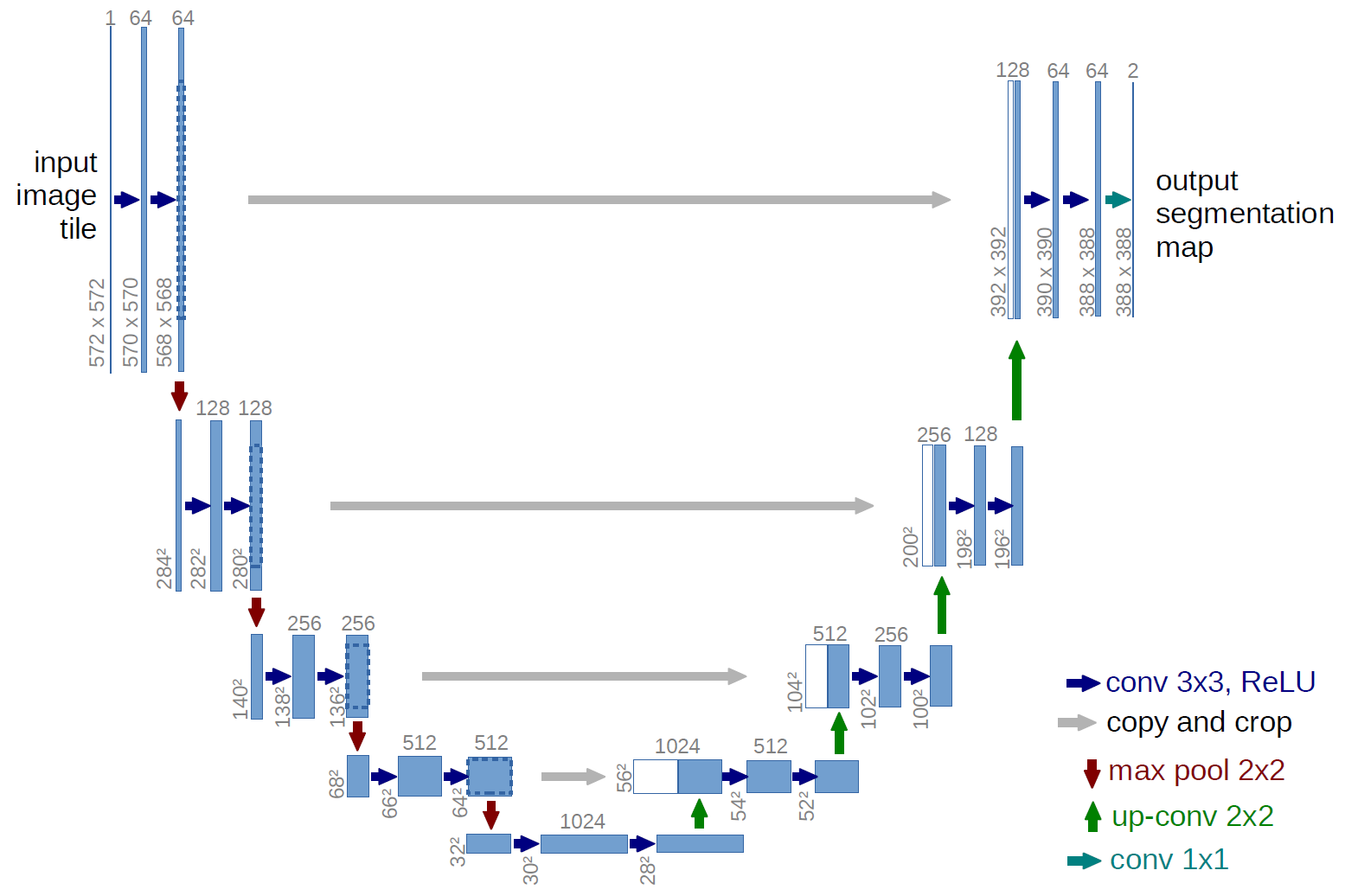
UNet Architecture has 3 parts:
- The Contracting/Downsampling Path
- Bottleneck
- The Expanding/Upsampling Path
Downsampling Path:
- It consists of two 3x3 convolutions (unpadded convolutions), each followed by a rectified linear unit (ReLU) and a 2x2 max pooling operation with stride 2 for downsampling.
- At each downsampling step we double the number of feature channels.
Upsampling Path:
- Every step in the expansive path consists of an upsampling of the feature map followed by a 2x2 convolution (“up-convolution”), a concatenation with the correspondingly feature map from the downsampling path, and two 3x3 convolutions, each followed by a ReLU.
Skip Connection:
The skip connection from the downsampling path are concatenated with feature map during upsampling path. These skip connection provide local information to global information while upsampling.Final Layer:
At the final layer a 1x1 convolution is used to map each feature vector to the desired number of classes.1.2 Advantages¶
Advantages:
- The UNet combines the location information from the downsampling path to finally obtain a general information combining localisation and context, which is necessary to predict a good segmentation map.
- No Dense layer is used, so image sizes can be used.
1.3 Dataset¶
Link: Data Science Bowl 2018 Find the nuclei in divergent images to advance medical discovery
1.4 Code¶
In [1]:
## Imports
import os
import sys
import random
import numpy as np
import cv2
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from keras import backend as K
## Seeding
seed = 2019
random.seed = seed
np.random.seed = seed
tf.seed = seed
Data Generator¶
In [2]:
from os import listdir
from os.path import isfile,join
class GetData():
def __init__(self, data_dir):
images_list =[]
labels_list = []
self.source_list = []
label_dir = os.path.join(data_dir, "Labels")
image_dir = os.path.join(data_dir, "Images")
self.image_size = 128
examples = 0
print("loading images")
onlyImagefiles = [f for f in listdir(image_dir) if isfile(join(image_dir, f))]
onlyLabelfiles = [f for f in listdir(label_dir) if isfile(join(label_dir, f))]
onlyImagefiles.sort()
onlyLabelfiles.sort()
for i in range (len(onlyImagefiles)):
image = cv2.imread(os.path.join(image_dir,onlyImagefiles[i]))
#im = Image.open(os.path.join(label_dir,onlyLabelfiles[i]),cv2.IMREAD_GRAYSCALE)
#label = np.array(im)
label = cv2.imread(os.path.join(label_dir,onlyLabelfiles[i]),cv2.IMREAD_GRAYSCALE)
#image= cv2.resize(image, (self.image_size, self.image_size))
#label= cv2.resize(label, (self.image_size, self.image_size))
image = image[96:224,96:224]
label = label[96:224,96:224]
#cv2.imwrite("Pre_"+str(i)+".jpg",label)
#image = image[...,0][...,None]/255
label = label>40
image = image/255
#image = image[...,None]
label = label[...,None]
label = label.astype(np.int32)
#label = label*255
#cv2.imwrite("Post_"+str(i)+".jpg",label)
images_list.append(image)
labels_list.append(label)
examples = examples +1
print("finished loading images")
self.examples = examples
print("Number of examples found: ", examples)
self.images = np.array(images_list)
self.labels = np.array(labels_list)
def next_batch(self, batch_size):
if len(self.source_list) < batch_size:
new_source = list(range(self.examples))
random.shuffle(new_source)
self.source_list.extend(new_source)
examples_idx = self.source_list[:batch_size]
del self.source_list[:batch_size]
return self.images[examples_idx,...], self.labels[examples_idx,...]
In [3]:
# Base Directory Directory
base_dir= 'Data'
# Training and Test Directories
train_dir = os.path.join(base_dir,'Train')
test_dir = os.path.join(base_dir,'Test')
real_dir = os.path.join(base_dir,'Real')
BATCH_SIZE = 1
BUFFER_SIZE = 1000
image_size = 128
EPOCHS = 20
def PreProcessImages():
train_data = GetData(train_dir)
test_data = GetData(test_dir)
real_data = GetData(real_dir)
return train_data, test_data, real_data
Hyperparameters¶
In [4]:
image_size = 128
epochs = 50
batch_size = 8
In [5]:
train_data, test_data, real_data= PreProcessImages()
fig = plt.figure()
fig.subplots_adjust(hspace=0.4, wspace=0.4)
ax = fig.add_subplot(1, 2, 1)
ax.imshow(train_data.images[3,:,:,:])
ax = fig.add_subplot(1, 2, 2)
ax.imshow(np.reshape(train_data.labels[3,:,:,:], (image_size, image_size)), cmap="gray")
Out[5]:

In [6]:
def ImportImages(train_data, test_data):
train_dataset=tf.data.Dataset.from_tensor_slices((train_data.images, train_data.labels)).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
test_dataset = tf.data.Dataset.from_tensor_slices((test_data.images, test_data.labels)).batch(BATCH_SIZE)
return train_dataset, test_dataset
Different Convolutional Blocks¶
In [7]:
def down_block(x, filters, kernel_size=(3, 3), padding="same", strides=1):
c = keras.layers.Conv2D(filters, kernel_size, padding=padding, strides=strides, activation="relu")(x)
c = keras.layers.Conv2D(filters, kernel_size, padding=padding, strides=strides, activation="relu")(c)
p = keras.layers.MaxPool2D((2, 2), (2, 2))(c)
return c, p
def up_block(x, skip, filters, kernel_size=(3, 3), padding="same", strides=1):
us = keras.layers.UpSampling2D((2, 2))(x)
concat = keras.layers.Concatenate()([us, skip])
c = keras.layers.Conv2D(filters, kernel_size, padding=padding, strides=strides, activation="relu")(concat)
c = keras.layers.Conv2D(filters, kernel_size, padding=padding, strides=strides, activation="relu")(c)
return c
def bottleneck(x, filters, kernel_size=(3, 3), padding="same", strides=1):
c = keras.layers.Conv2D(filters, kernel_size, padding=padding, strides=strides, activation="relu")(x)
c = keras.layers.Conv2D(filters, kernel_size, padding=padding, strides=strides, activation="relu")(c)
return c
UNet Model¶
In [8]:
def UNet():
f = [16, 32, 64, 128, 256]
inputs = keras.layers.Input((image_size, image_size, 3))
p0 = inputs
c1, p1 = down_block(p0, f[0]) #128 -> 64
c2, p2 = down_block(p1, f[1]) #64 -> 32
c3, p3 = down_block(p2, f[2]) #32 -> 16
c4, p4 = down_block(p3, f[3]) #16->8
bn = bottleneck(p4, f[4])
u1 = up_block(bn, c4, f[3]) #8 -> 16
u2 = up_block(u1, c3, f[2]) #16 -> 32
u3 = up_block(u2, c2, f[1]) #32 -> 64
u4 = up_block(u3, c1, f[0]) #64 -> 128
outputs = keras.layers.Conv2D(1, (1, 1), padding="same", activation="sigmoid")(u4)
model = keras.models.Model(inputs, outputs)
return model
In [9]:
def f1_metric(y_true, y_pred):
y_true = y_true >0.4
y_pred = y_pred>0.4
y_true = tf.dtypes.cast(y_true,tf.float32)
y_pred = tf.dtypes.cast(y_pred,tf.float32)
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
recall = true_positives / (possible_positives + K.epsilon())
f1_val = 2*(precision*recall)/(precision+recall+K.epsilon())
return f1_val
In [10]:
def dice_coef(y_true, y_pred, smooth=1):
y_true = y_true >0.4
y_pred = y_pred>0.4
y_true = tf.dtypes.cast(y_true,tf.float32)
y_pred = tf.dtypes.cast(y_pred,tf.float32)
intersection = K.sum(K.abs(y_true * y_pred), axis=-1)
return(2. * intersection + smooth) / (K.sum(K.square(y_true),-1) + K.sum(K.square(y_pred),-1) + smooth)
In [11]:
model = UNet()
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=[f1_metric,dice_coef])
model.summary()
Training the model¶
In [12]:
train_data, test_data, real_data= PreProcessImages()
train_dataset, test_dataset= ImportImages(train_data, test_data)
train_steps = len(train_data.labels)//batch_size
valid_steps = len(test_data.labels)//batch_size
#model.fit_generator(train_data, validation_data=test_data, steps_per_epoch=train_steps, validation_steps=valid_steps,
# epochs=epochs)
model_history = model.fit(train_data.images,train_data.labels,validation_split=0.3, epochs=epochs)
Testing the model¶
In [13]:
## Save the Weights
model.save_weights("UNetW.h5")
## Dataset for prediction
resultCross = model.predict(test_data.images)
resultSame = model.predict(real_data.images)
resultCross = resultCross > 0.4
resultSame = resultSame >0.4
score = model.evaluate(test_data.images,test_data.labels)
print("Cross Domain Loss: "+str(score[0]))
print("Cross Domain F1 score: "+str(score[1]))
print("Cross Domain Accuracy: "+str(score[2]))
score = model.evaluate(real_data.images,real_data.labels)
print("Real Domain Loss: "+str(score[0]))
print("Real Domain F1 score: "+str(score[1]))
print("Real Domain Accuracy: "+str(score[2]))
In [14]:
for i in range (20):
fig = plt.figure(figsize=(15,15))
#fig.subplots(1,3,figsize=(15,15))
fig.subplots_adjust(hspace=1, wspace=1)
ax = fig.add_subplot(1, 3, 1)
ax.imshow(test_data.images[i,:,:,:])
ax.title.set_text("CD Image " + str(i))
ax = fig.add_subplot(1, 3, 2)
ax.imshow(np.reshape(test_data.labels[i,:,:,:]*255, (image_size, image_size)), cmap="gray")
ax.title.set_text("CD Ground Truth "+ str(i))
ax = fig.add_subplot(1, 3, 3)
ax.imshow(np.reshape(resultCross[i]*255, (image_size, image_size)), cmap="gray")
ax.title.set_text("CD Predicted "+ str(i))
ax = fig.add_subplot(2, 3, 1)
ax.imshow(real_data.images[i,:,:,:])
ax.title.set_text("SD Image "+ str(i))
ax = fig.add_subplot(2, 3, 2)
ax.imshow(np.reshape(real_data.labels[i,:,:,:]*255, (image_size, image_size)), cmap="gray")
ax.title.set_text("SD Ground Truth " + str(i))
ax = fig.add_subplot(2, 3, 3)
ax.imshow(np.reshape(resultSame[i]*255, (image_size, image_size)), cmap="gray")
ax.title.set_text("SD Predicted "+ str(i))




















In [ ]:
In [ ]: